Pairwise fitting
Last updated: 2022-08-14
Checks: 6 1
Knit directory: workflowr/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20190717) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
- unnamed-chunk-3
- unnamed-chunk-6
To ensure reproducibility of the results, delete the cache directory
pairwise_fitting_cache and re-run the analysis. To have
workflowr automatically delete the cache directory prior to building the
file, set delete_cache = TRUE when running
wflow_build() or wflow_publish().
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 061748a. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rproj.user/
Ignored: analysis/DNase_example_cache/
Ignored: analysis/running_mcmc_cache/
Ignored: data/DHS_Index_and_Vocabulary_hg38_WM20190703.txt
Ignored: data/DNase_chr21/
Ignored: data/DNase_chr22/
Ignored: data/dat_FDR01_hg38.RData
Ignored: output/DNase/
Untracked files:
Untracked: data/DHS_Index_and_Vocabulary_hg38_WM20190703.txt.gz
Untracked: data/DHS_Index_and_Vocabulary_metadata.xlsx
Unstaged changes:
Modified: analysis/.DS_Store
Modified: analysis/DNase_example.Rmd
Modified: analysis/pairwise_fitting_cache/html/__packages
Deleted: analysis/pairwise_fitting_cache/html/unnamed-chunk-3_49e4d860f91e483a671b4b64e8c81934.RData
Deleted: analysis/pairwise_fitting_cache/html/unnamed-chunk-3_49e4d860f91e483a671b4b64e8c81934.rdb
Deleted: analysis/pairwise_fitting_cache/html/unnamed-chunk-3_49e4d860f91e483a671b4b64e8c81934.rdx
Deleted: analysis/pairwise_fitting_cache/html/unnamed-chunk-6_4e13b65e2f248675b580ad2af3613b06.RData
Deleted: analysis/pairwise_fitting_cache/html/unnamed-chunk-6_4e13b65e2f248675b580ad2af3613b06.rdb
Deleted: analysis/pairwise_fitting_cache/html/unnamed-chunk-6_4e13b65e2f248675b580ad2af3613b06.rdx
Modified: analysis/preprocessing_cache/html/__packages
Deleted: analysis/preprocessing_cache/html/unnamed-chunk-11_d0dcbf60389f2e00d36edbf7c0da270d.RData
Deleted: analysis/preprocessing_cache/html/unnamed-chunk-11_d0dcbf60389f2e00d36edbf7c0da270d.rdb
Deleted: analysis/preprocessing_cache/html/unnamed-chunk-11_d0dcbf60389f2e00d36edbf7c0da270d.rdx
Modified: data/.DS_Store
Modified: data/tpm_zebrafish.tsv.gz
Modified: output/.DS_Store
Deleted: output/chain.rds
Modified: output/hyperparameters.Rdata
Modified: output/red_class.txt
Modified: output/retained_classes.txt
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/pairwise_fitting.Rmd) and
HTML (docs/pairwise_fitting.html) files. If you’ve
configured a remote Git repository (see ?wflow_git_remote),
click on the hyperlinks in the table below to view the files as they
were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | f1a7b55 | Hillary Koch | 2022-08-13 | add DNase analysis |
| html | f1a7b55 | Hillary Koch | 2022-08-13 | add DNase analysis |
| Rmd | c1e13d0 | Hillary Koch | 2022-07-30 | working with new computer |
| html | c1e13d0 | Hillary Koch | 2022-07-30 | working with new computer |
—Special considerations: this portion is highly parallelizable—
Here, we describe how to execute the first step of CLIMB: pairwise fitting (a composite likelihood method).
First, load the package and the simulated dataset. This toy dataset has \(n=1500\) observations across \(D=3\) conditions (that is, dimensions). Thus, we need to fit \(\binom{D}{2}=3\) pairwise models.
# load that package
library(CLIMB)
# load the toy data
data("sim")The fitting of each pairwise model can be done in parallel, which
saves a lot of computing time when the dimension is larger. This can be
done simply (in parallel, or linearly) with the function
get_pairwise_fits(). Note that the input data should be
\(z\)-scores (or data arising from some
other scoring mechanism, transformed appropriately to \(z\)-scores).
get_pairwise_fits() runs the pairwise analysis at the
default settings used in the CLIMB manuscript. The user can select a few
settings with this functions:
nlambda: how many tuning parameters to try (defaults to 10)parallel: logical indicating whether or not to do the analysis in parallelncores: if in parallel, how many cores to use (defaults to 10)bound: is there a lower bound on the estimated non-null mean? (defaults to zero, and must be non-negative)flex_mu: should we loosen restrictions on the mean in the pairwise fitting (defaults to FALSE, best used in conjunction withbound)?
With all of this in place, one can obtain the pairwise fits as follows:
fits <- get_pairwise_fits(z = sim$data, parallel = FALSE)Calling names(fits) tells us which pair of dimensions
each fit belongs to.
names(fits)[1] "1_2" "1_3" "2_3"It is advisable to take a look at the pairwise fitting output before proceeding, just to make sure things have gone ok so far.
axis_names <- names(fits) %>% stringr::str_split("_")
par(mfrow = c(1,3))
purrr::map2(.x = fits, .y = axis_names,
~ plot(sim$data[, as.numeric(.y)], col = .x$cluster, pch = 4))
The default settings of get_pairwise_fits() are
generally sufficient for analysis. However, it makes some modeling
assumptions which can be relaxed. Namely, if one wants a slightly more
flexible model based on estimation of cluster means, one could instead
run the following:
# bound = qnorm(0.9) says that the magnitude of the estimated cluster means
# (for clusters whose mean is non-zero) must be at least the 90% quantile
# of a standard normal distribution
flexible_fits <-
get_pairwise_fits(
z = sim$data,
parallel = FALSE,
flex_mu = TRUE,
bound = qnorm(0.9)
)This change is sometimes desirable in cases where the data are highly
skewed. It is recommended to set some positive bound when
flex_mu=TRUE. If not, one is likely to underestimate the
true number of clusters. We can see that, in this case, classification
appears similar to the previous version with flex_mu=FALSE
and bound=0.
axis_names <- names(flexible_fits) %>% stringr::str_split("_")
par(mfrow = c(1,3))
purrr::map2(.x = flexible_fits, .y = axis_names,
~ plot(sim$data[, as.numeric(.y)], col = .x$cluster, pch = 4))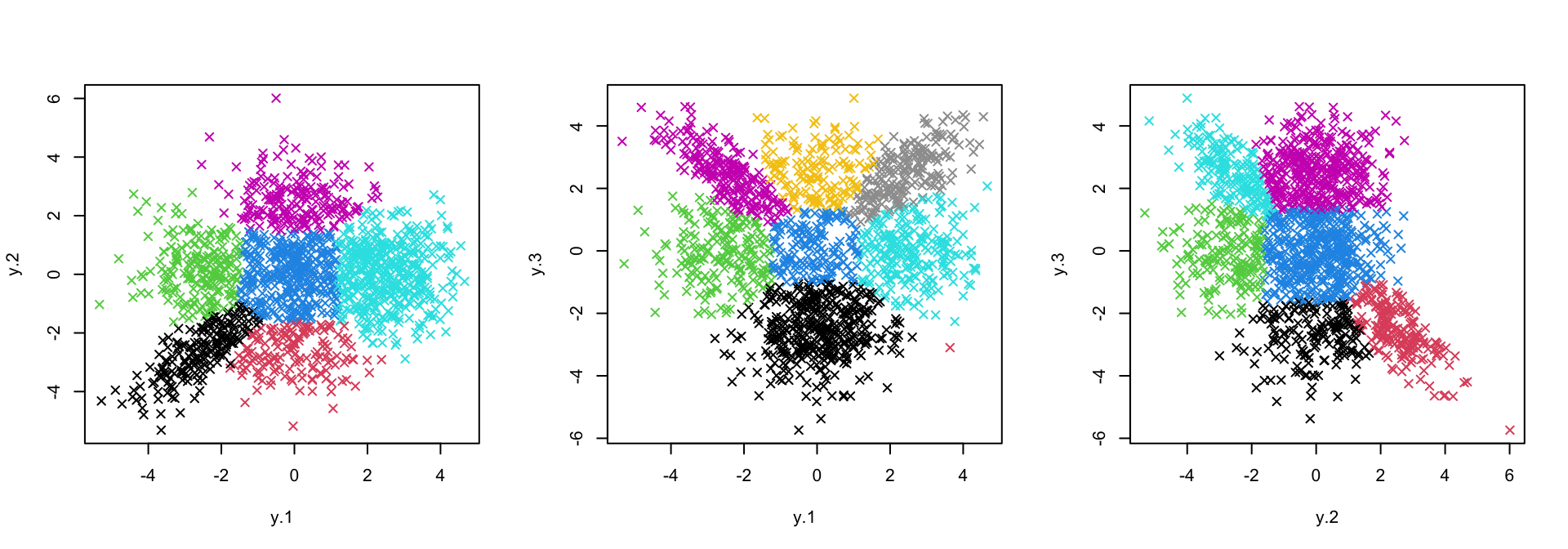
Each fit contains additional information, including the length-2 association patterns estimated to be in the given pairwise fit, the posterior probability of each observation belonging to each of these classes, and their corresponding estimated means and covariances.
Finally, save this output, as it is necessary for many parts of the downstream analyses, before moving on to the next step.
save(fits, file = "pwfits.Rdata")Session Information
print(sessionInfo())R version 4.2.1 (2022-06-23)
Platform: aarch64-apple-darwin20 (64-bit)
Running under: macOS Monterey 12.5
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.2-arm64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.2-arm64/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] magrittr_2.0.3 CLIMB_1.0.0
loaded via a namespace (and not attached):
[1] tidyselect_1.1.2 xfun_0.31 bslib_0.4.0
[4] purrr_0.3.4 testthat_3.1.4 vctrs_0.4.1
[7] generics_0.1.3 htmltools_0.5.3 yaml_2.3.5
[10] utf8_1.2.2 rlang_1.0.4 jquerylib_0.1.4
[13] later_1.3.0 pillar_1.8.0 glue_1.6.2
[16] DBI_1.1.3 foreach_1.5.2 lifecycle_1.0.1
[19] plyr_1.8.7 stringr_1.4.0 workflowr_1.7.0
[22] mvtnorm_1.1-3 LaplacesDemon_16.1.6 codetools_0.2-18
[25] evaluate_0.15 knitr_1.39 tzdb_0.3.0
[28] fastmap_1.1.0 doParallel_1.0.17 httpuv_1.6.5
[31] parallel_4.2.1 fansi_1.0.3 highr_0.9
[34] Rcpp_1.0.9 readr_2.1.2 promises_1.2.0.1
[37] cachem_1.0.6 jsonlite_1.8.0 abind_1.4-5
[40] fs_1.5.2 brio_1.1.3 hms_1.1.1
[43] digest_0.6.29 stringi_1.7.8 dplyr_1.0.9
[46] rprojroot_2.0.3 cli_3.3.0 tools_4.2.1
[49] sass_0.4.2 tibble_3.1.8 whisker_0.4
[52] tidyr_1.2.0 pkgconfig_2.0.3 ellipsis_0.3.2
[55] assertthat_0.2.1 rmarkdown_2.14 rstudioapi_0.13
[58] iterators_1.0.14 JuliaCall_0.17.4 R6_2.5.1
[61] git2r_0.30.1 compiler_4.2.1