Downstream analysis
Last updated: 2022-08-13
Checks: 6 1
Knit directory: workflowr/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
The R Markdown file has unstaged changes. To know which version of
the R Markdown file created these results, you’ll want to first commit
it to the Git repo. If you’re still working on the analysis, you can
ignore this warning. When you’re finished, you can run
wflow_publish to commit the R Markdown file and build the
HTML.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20190717) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version e4f6d19. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rproj.user/
Ignored: analysis/DNase_example_cache/
Ignored: analysis/running_mcmc_cache/
Ignored: data/DHS_Index_and_Vocabulary_hg38_WM20190703.txt
Ignored: data/DNase_chr21/
Ignored: data/DNase_chr22/
Ignored: data/dat_FDR01_hg38.RData
Ignored: output/DNase/
Untracked files:
Untracked: data/DHS_Index_and_Vocabulary_metadata.xlsx
Untracked: data/biosamples_used.xlsx
Untracked: data/color_mapper.txt
Unstaged changes:
Modified: analysis/DNase_example.Rmd
Modified: analysis/candidate_latent_classes.Rmd
Modified: analysis/downstream.Rmd
Modified: analysis/index.Rmd
Modified: analysis/pairwise_fitting.Rmd
Modified: analysis/pairwise_fitting_cache/html/__packages
Deleted: analysis/pairwise_fitting_cache/html/unnamed-chunk-3_49e4d860f91e483a671b4b64e8c81934.RData
Deleted: analysis/pairwise_fitting_cache/html/unnamed-chunk-3_49e4d860f91e483a671b4b64e8c81934.rdb
Deleted: analysis/pairwise_fitting_cache/html/unnamed-chunk-3_49e4d860f91e483a671b4b64e8c81934.rdx
Deleted: analysis/pairwise_fitting_cache/html/unnamed-chunk-6_4e13b65e2f248675b580ad2af3613b06.RData
Deleted: analysis/pairwise_fitting_cache/html/unnamed-chunk-6_4e13b65e2f248675b580ad2af3613b06.rdb
Deleted: analysis/pairwise_fitting_cache/html/unnamed-chunk-6_4e13b65e2f248675b580ad2af3613b06.rdx
Modified: analysis/preprocessing.Rmd
Modified: analysis/preprocessing_cache/html/__packages
Deleted: analysis/preprocessing_cache/html/unnamed-chunk-11_d0dcbf60389f2e00d36edbf7c0da270d.RData
Deleted: analysis/preprocessing_cache/html/unnamed-chunk-11_d0dcbf60389f2e00d36edbf7c0da270d.rdb
Deleted: analysis/preprocessing_cache/html/unnamed-chunk-11_d0dcbf60389f2e00d36edbf7c0da270d.rdx
Modified: analysis/priors.Rmd
Modified: analysis/running_mcmc.Rmd
Modified: data/tpm_zebrafish.tsv.gz
Modified: output/.DS_Store
Staged changes:
New: .Renviron
Modified: .gitignore
New: analysis/DNase_example.Rmd
Modified: analysis/_site.yml
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/downstream.Rmd) and HTML
(docs/downstream.html) files. If you’ve configured a remote
Git repository (see ?wflow_git_remote), click on the
hyperlinks in the table below to view the files as they were in that
past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | c1e13d0 | Hillary Koch | 2022-07-30 | working with new computer |
| html | c1e13d0 | Hillary Koch | 2022-07-30 | working with new computer |
CLIMB’s output is nothing but the posterior MCMC samples of the parameters of the normal mixture (means, variance-covariance matrices, mixing weights, and cluster assignments). These samples can be used for clustering/classification, visualizations, and statistical inference. While there are many downstream analyses one could do with such output, here, we demonstrate implementations of several of the analyses used in the CLIMB manuscript.
First, let’s load in the MCMC we briefly ran on simulated data in the running the MCMC section.
chain <- readRDS("output/chain.rds")Visualizing convergence
The first thing we should do make some trace plots for some of the parameters being estimated. This will help us decide when the chain has entered its stationary distribution. Here, we make plots of a mean, variance, covariance, and mixing weight.
# The mean in the first dimension of the third cluster
mu31 <- chain$mu_chains[[3]][,1]
# The variance of the first dimension of the second cluster
sigma21 <- chain$Sigma_chains[[2]][1,1,]
# The covariance between dimensions 2 and 3 in the fourth cluster
sigma423 <- chain$Sigma_chains[[4]][2,3,]
# The mixing weight of the seventh cluster
pi7 <- chain$prop_chain[,7]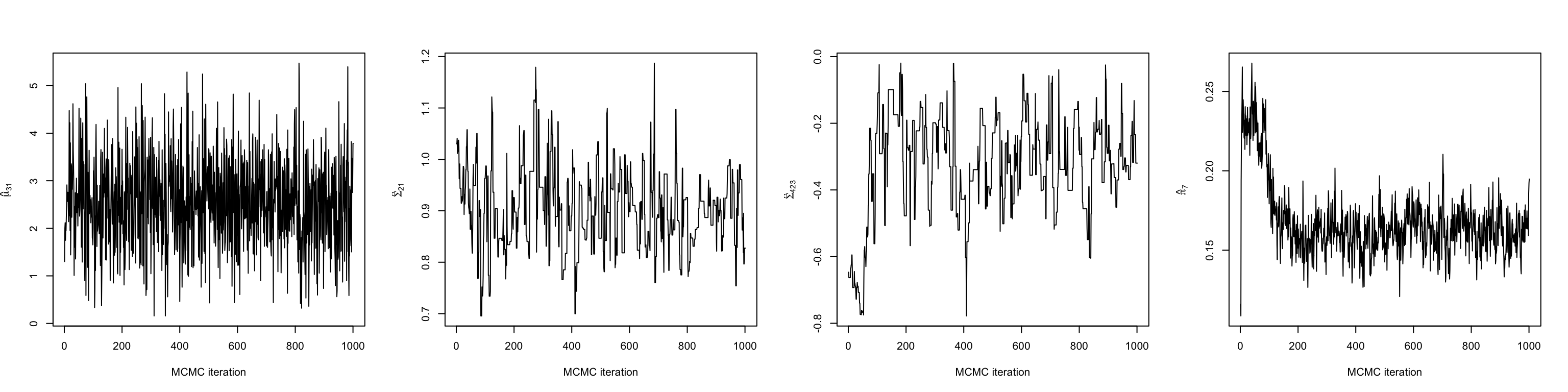
| Version | Author | Date |
|---|---|---|
| c1e13d0 | Hillary Koch | 2022-07-30 |
Looking at a few of these trace plots reveals that the chain achieves stationary around 200 iterations in. Therefore, we discard the first 200 iterations as burn-in, and do our analyses on the remaining 800.
burnin <- 1:200Clustering dimensions and observations
CLIMB can provide a bi-clustering of analyzed data. Row clusters come from the estimated latent classes, of course, though these classes can even be grouped by their similarity.
CLIMB uses a distance based on class covariances to cluster the
dimensions (columns). The function
compute_distances_between_conditions will compute these
pairwise distances between conditions based on model fit. This was used
in the CLIMB manuscript to determine the relationship among
hematopoietic cell populations based on CTCF binding patterns.
CLIMB’s estimated classes naturally cluster the rows. However, the
function compute_distances_between_clusters will compute
distances between estimated clusters as well. This distance is based on
a symmetrified theoretical Kullback-Liebler divergence.
par(mfrow = c(1,2))
# The figure isn't as exciting with simulated data
col_distmat <- compute_distances_between_conditions(chain, burnin)
hc_col <- hclust(as.dist(col_distmat), method = "complete")
plot(hc_col, xlab = "", ylab= "", axes = FALSE, sub = "", main = "Row cluster dendrogram")
row_distmat <- compute_distances_between_clusters(chain, burnin)
hc_row <- hclust(as.dist(row_distmat), method = "complete")
plot(hc_row, xlab = "", ylab= "", axes = FALSE, sub = "", main = "Column cluster dendrogram")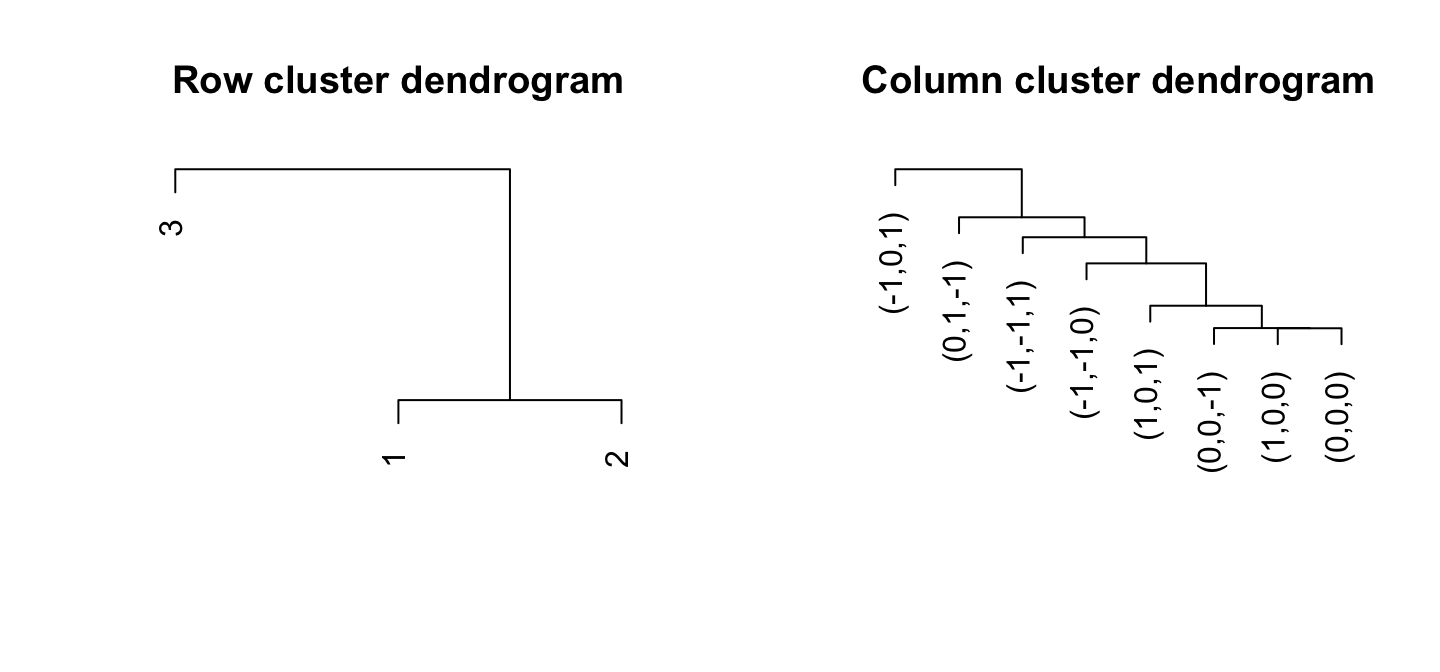
| Version | Author | Date |
|---|---|---|
| c1e13d0 | Hillary Koch | 2022-07-30 |
These figures aren’t very thrilling on their own, but we can use them
to make some nice heatmaps. CLIMB provides the function
get_row_reordering to facilitate plotting the
bi-clustering:
# Load back in the data
data("sim")
dat <- sim$data
# Get a row reordering for plotting
row_reordering <- get_row_reordering(dat = dat, row_clustering = hc_row, chain = chain, burnin = burnin)
# Melt (for ggplot2)
molten1 <-
dplyr::mutate(dat, "row" = row_reordering) %>%
tidyr::pivot_longer(cols=!row, names_to = "variable")
# Rename the factor levels to match the dimensions
levels(molten1$variable) <- as.factor(paste(1:3))
# Plot the bi-clustering heatmap, like in the CLIMB manuscript
p1 <- ggplot(data = molten1,
aes(x = forcats::fct_relevel(variable, ~ .x[hc_col$order]), # Relevel factors, for column sorting on the plot
y = row, fill = value)) +
geom_raster() +
cowplot::theme_cowplot() +
theme(legend.position = "none", axis.ticks.y = element_blank(), axis.text.y = element_blank()) +
xlab("") + ylab("") +
theme(axis.text.x = element_text(angle = 90, hjust = 1, vjust = .5)) +
ggtitle("Bi-clustering\nheatmap") +
scale_fill_gradientn(colours=RColorBrewer::brewer.pal(9,"Greens"))
print(p1)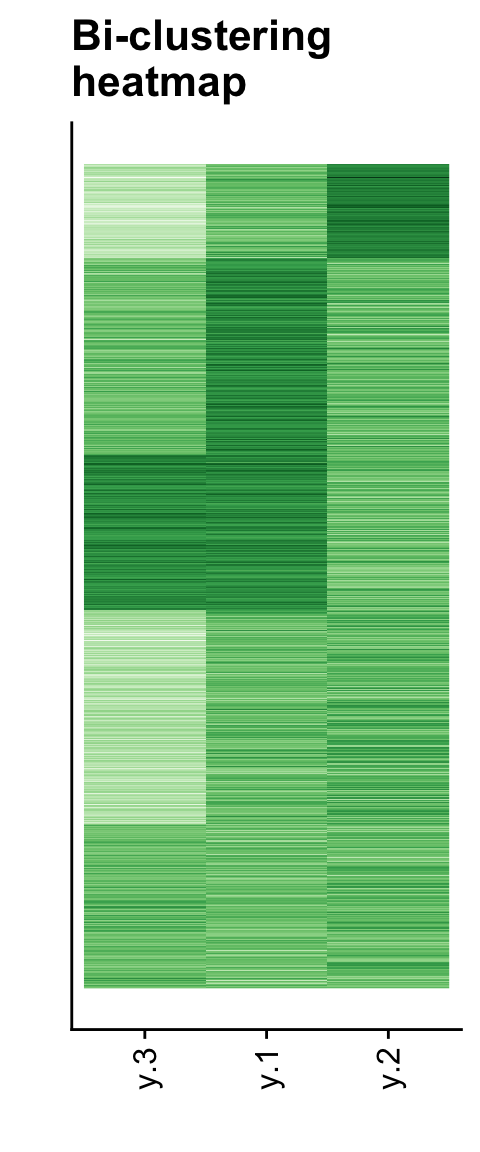
| Version | Author | Date |
|---|---|---|
| c1e13d0 | Hillary Koch | 2022-07-30 |
Merging groups
CLIMB allows you to merge similar groups for the sake of
visualization, for examble on the Genome Browser. In the CLIMB
manuscript, we merged clusters of CTCF binding patterns to color peaks
more in a more parsimonious set of 5 groups on the genome browser. We
show how to do this for an arbitrary number of groups with CLIMB’s
merge_classes function.
The output of a merge_classes call provides the means
and mixing weights of the new parent groups. These means and weights are
aggregated from each groups constituent classes. merged_z
gives the new group assignments for each observations.
The clustering obect is simply a call to
stats::hclust().
# Merge into 5 parent groups
merged <- merge_classes(n_groups = 5, chain = chain, burnin = burnin)
# Check the structure of the merging
str(merged)List of 6
$ merged_z : int [1:1500] 5 1 1 1 1 1 1 1 1 1 ...
$ merged_mu : num [1:5, 1:3] 1.194 0 -2.521 -0.653 -2.541 ...
$ merged_sigma: num [1:3, 1:3, 1:5] 0.95 0 0.102 0 1 ...
$ merged_prop : num [1:5] 0.5756 0.0758 0.1254 0.1043 0.1189
$ clustering :List of 7
..$ merge : int [1:7, 1:2] -2 -5 -1 -3 -8 -7 -6 -4 1 2 ...
..$ height : num [1:7] 0.00248 0.00439 0.34847 0.72599 0.87559 ...
..$ order : int [1:8] 6 7 8 3 1 5 2 4
..$ labels : chr [1:8] "1" "2" "4" "6" ...
..$ method : chr "average"
..$ call : language hclust(d = as.dist(cluster_dist), method = method)
..$ dist.method: NULL
..- attr(*, "class")= chr "hclust"
$ distmat : num [1:8, 1:8] 0 0.347 1.467 0.365 0.333 ...
..- attr(*, "dimnames")=List of 2
.. ..$ : chr [1:8] "1" "2" "4" "6" ...
.. ..$ : chr [1:8] "1" "2" "4" "6" ...We can visualize the salient features of the new groups with a simple visualization of the merged group means:
# For the plot color palette
library(RColorBrewer)
# Melt for plotting
molten2 <-
merged$merged_mu %>%
`colnames<-` (paste0("cond", 1:3)) %>%
as.data.frame() %>%
dplyr::mutate(group = 1:n()) %>%
tidyr::pivot_longer(cols = !group, names_to = "condition", values_to = "mu")
p2 <- ggplot(data = molten2, aes(group, condition, fill = mu)) +
geom_tile(color = "black") +
scale_fill_distiller(palette = "PiYG", direction = 1) +
coord_fixed() +
theme_minimal() +
theme(axis.text.x = element_text(angle = 0, vjust = 0.5, hjust = 1, size = 18),
axis.text.y = element_text(size = 20),
axis.title.x = element_text(size = 18),
axis.ticks.y = element_blank(),
axis.ticks.x = element_blank(),
legend.title = element_text(size = 12))
print(p2)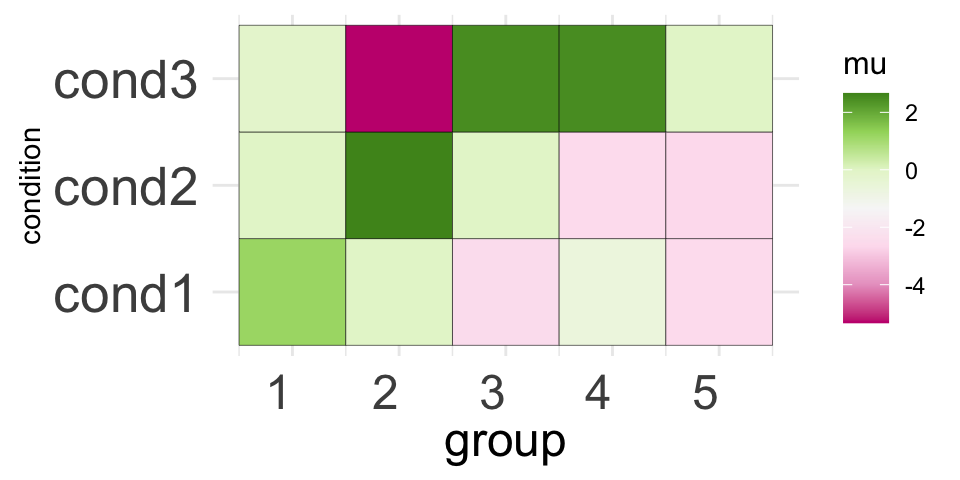
| Version | Author | Date |
|---|---|---|
| c1e13d0 | Hillary Koch | 2022-07-30 |
Testing for consistency
In the CLIMB manuscript, we introduce a statistical test for consistency of signals based on the partial conjunction hypothesis:
\[\begin{equation} \begin{aligned} \mathcal{H}_0^{u/D} &:= \text{less than }u\text{ out of }D\text{ instances of the observed effect are non-null, versus }\\ \mathcal{H}_1^{u/D} &:= \text{at least }u\text{ out of }D\text{ instances of the observed effect are non-null} \end{aligned} \end{equation}\]
where \(u\) is some user-defined consistency threshold, and \(D\) is the dimension of the data. This hypothesis is texting using some combination of the following quantites:
\[\begin{align} &P^{u/D+}:=\sum_{m=1}^M \text{Pr}(\mathbf{x}_i\in h_m \mid \mathbf{x}) \cdot \mathbf{1} \big[ \sum_{d=1}^D \mathbf{1} (h_{[d]}^m=1) \geq u\big] \tag{a}\\ &P^{u/D0} := \sum_{m=1}^M \text{Pr}(\mathbf{x}_i\in h_m \mid \mathbf{x})\cdot\mathbf{1}\big[\sum_{d=1}^D\mathbf{1}(h_{[d]}^m=0) \geq u\big] \tag{b} \\ &P^{u/D-}:=\sum_{m=1}^M \text{Pr}(\mathbf{x}_i\in h_m \mid \mathbf{x})\cdot\mathbf{1}\big[\sum_{d=1}^D\mathbf{1}(h_{[d]}^m=-1) \geq u\big] \tag{c} \\ &P^{u/D}:=\sum_{m=1}^M \text{Pr}(\mathbf{x}_i\in h_m \mid \mathbf{x})\cdot\mathbf{1}\big[\sum_{d=1}^D\mathbf{1}(h_{[d]}^m \neq 0) \geq u\big] \tag{d} \end{align}\]
Which quantities you use depends on what you want to test. If you want to test whether some signals are replicated, and you care about the sign of the signals, you would employ a replicability test with quantities (a) and (c). If you wanted to do the same test, but you are agnostic to the sign of the signal, you would employ quantity (d) instead. If you wanted to test for consistent behavior (e.g., what is done in the CLIMB manuscript for differential gene expression along a lineage), you would employ a test using quantites (a), (b), and (c).
This is all implemented in the CLIMB function
test_consistency. Test consistency takes 6 arguments.
chain: the output ofextract_chains()burnin: a vector of iterations (indices) to be used as burn-inu: the consistency threshold, which is an integer in \(2\ldots D\)b: the confidence level in (0,1), corresponding the posterior probability that an observation rejects the null hypothesis. Here, a natural threshold is 0.5, though larger, more stringent thresholds could be applied.with_zero: Set this equal toTRUEto implement the test for consistency across all dimensions, as in the CLIMB manuscript when testing for differentially expressed genes.agnostic_to_sign: Set equal toTRUEif you do not care if a signal is in the positive or negative directions.
This function will return a boolean vector with \(n\) elements (\(n\) being the sample size). If returns
TRUE when the null is rejected.
So, for example, we can test for which simulated observations are “consistently expressed” across all 3 dimensions as follows:
non_differential <- test_consistency(chain, burnin, with_zero = TRUE)
head(non_differential)[1] FALSE FALSE FALSE TRUE FALSE FALSEHere, TRUE sits at the indices of observations who are
likely to be consistent across all 3 dimensions.
Alternatively, we could test for observations which show a consistent signal (i.e., a -1 or a 1) in at least 2 out of the 3 dimensions. Let’s do this, and also make a precision-recall curve displaying the results. To make a precision-recall curve, we first need to know the underlying truth of the simulation.
#-------------------------------------------------------------------------------
# First, obtain the truth
# Load in true association patterns
data("true_association")
# Consistency threshold
u <- 2
# Which indices correspond to consistent signals at threshold u = 2?
consistent_pos_lab_idx <- apply(true_assoc, 1, function(X) sum(X == 1) >= u)
consistent_neg_lab_idx <- apply(true_assoc, 1, function(X) sum(X == -1) >= u)
consistent_lab_idx <-
sort(unique(c(
which(consistent_neg_lab_idx),
which(consistent_pos_lab_idx)
)))
# These are the labels corresponding to consistent behavior
consistent_lab_idx[1] 3 8Now, we can compute precision and recall across a range of
b in (0,1).
b_grid <- seq(0, 1, length.out = 1000)
replicable <- test_consistency(chain, burnin, u = 2, b = b_grid)
# Which observations are the replicable ones
rep_idx <- sim$cluster %in% consistent_lab_idx
# Total number of positives in the dataset
P <- sum(rep_idx)
# True positives
TP <- map(replicable, ~ .x & rep_idx)
# False positives
FP <- map(replicable, ~ .x & !rep_idx)
# True positive rate aka recall
recall <- map_dbl(TP, ~ sum(.x) / P)
# precision
precision <- map2_dbl(TP, FP, ~ sum(.x) / (sum(.x) + sum(.y)))
# Plot
df <- data.frame("recall" = recall, "precision" = precision)
p3 <- ggplot(data = df, aes(x = recall, y = precision)) +
geom_line() +
# This horizontal line is the true proportion of replicable observations
geom_hline(yintercept = mean(rep_idx), lty = 2, color = "darkcyan") +
lims(x = c(0,1), y = c(0,1)) +
theme_minimal()
p3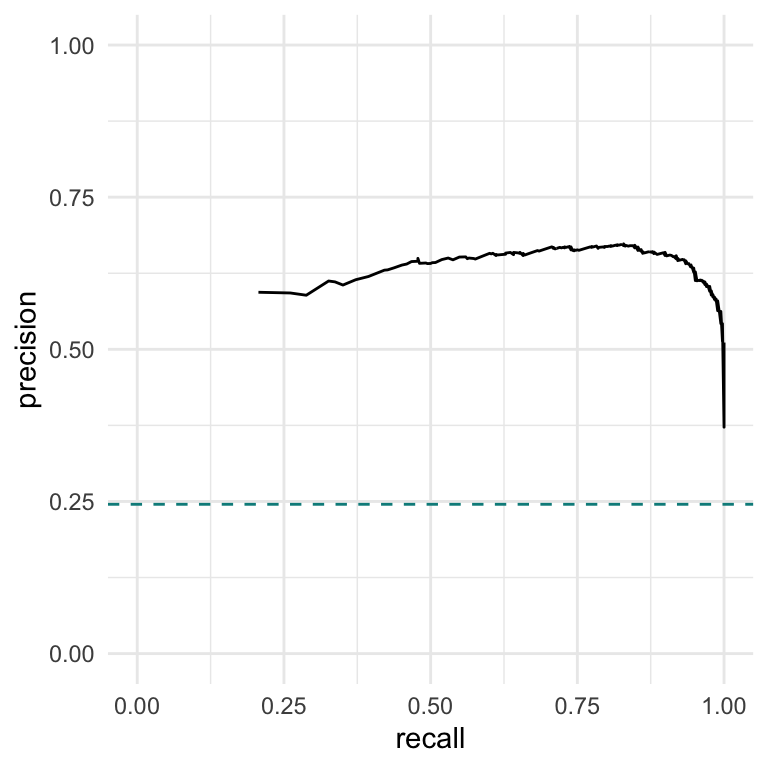
| Version | Author | Date |
|---|---|---|
| c1e13d0 | Hillary Koch | 2022-07-30 |
Multiple chains
It is possible that one might want to do downstream analysis on
multiple outputs from different CLIMB analyses. For example, you may be
using CLIMB to analyze ChIP- or ATAC-seq data genome-wide. Due to
computational considerations, you may have analyzed each chromosome
separately. Then, you will have ~20 different MCMC chains that you could
consider together for downstream analysis. CLIMB facilitates analyses
with the above functions with the addition of the
multichain argument. For the functions
compute_distances_between_conditionscompute_distances_between_clustersget_row_reorderingmerge_classes
if the argument multichain is set to TRUE,
then CLIMB will expect that you pass a list of MCMC outputs,
rather than just 1. A list of burn-in values for each chain can be
supplied, or 1 set of burn-in can be applied uniformly across all
chains.
Session Information
print(sessionInfo())R version 4.2.1 (2022-06-23)
Platform: aarch64-apple-darwin20 (64-bit)
Running under: macOS Monterey 12.5
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.2-arm64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.2-arm64/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] RColorBrewer_1.1-3 ggplot2_3.3.6 purrr_0.3.4 CLIMB_1.0.0
[5] dplyr_1.0.9
loaded via a namespace (and not attached):
[1] Rcpp_1.0.9 mvtnorm_1.1-3 tidyr_1.2.0
[4] assertthat_0.2.1 rprojroot_2.0.3 digest_0.6.29
[7] foreach_1.5.2 utf8_1.2.2 R6_2.5.1
[10] plyr_1.8.7 evaluate_0.15 highr_0.9
[13] pillar_1.8.0 rlang_1.0.4 rstudioapi_0.13
[16] whisker_0.4 jquerylib_0.1.4 rmarkdown_2.14
[19] labeling_0.4.2 readr_2.1.2 stringr_1.4.0
[22] munsell_0.5.0 compiler_4.2.1 httpuv_1.6.5
[25] xfun_0.31 pkgconfig_2.0.3 htmltools_0.5.3
[28] tidyselect_1.1.2 tibble_3.1.8 workflowr_1.7.0
[31] codetools_0.2-18 JuliaCall_0.17.4 fansi_1.0.3
[34] withr_2.5.0 tzdb_0.3.0 later_1.3.0
[37] brio_1.1.3 grid_4.2.1 jsonlite_1.8.0
[40] gtable_0.3.0 lifecycle_1.0.1 DBI_1.1.3
[43] git2r_0.30.1 magrittr_2.0.3 scales_1.2.0
[46] cli_3.3.0 stringi_1.7.8 cachem_1.0.6
[49] farver_2.1.1 LaplacesDemon_16.1.6 fs_1.5.2
[52] promises_1.2.0.1 doParallel_1.0.17 testthat_3.1.4
[55] bslib_0.4.0 ellipsis_0.3.2 generics_0.1.3
[58] vctrs_0.4.1 cowplot_1.1.1 forcats_0.5.1
[61] iterators_1.0.14 tools_4.2.1 glue_1.6.2
[64] hms_1.1.1 abind_1.4-5 parallel_4.2.1
[67] fastmap_1.1.0 yaml_2.3.5 colorspace_2.0-3
[70] knitr_1.39 sass_0.4.2